Engineering
기능이 늘어난 엔진을 더 빠르게 만들기
현재 production engine image와 새 engine build를 같은 amd64 Docker/RPC 조건에서 비교했다. Graph, hybrid keyword, content lookup까지 포함한 실제 RAG workload에서 어떤 변화가 있었는지 기록한다.
엔진 최적화 이야기는 보통 vector search latency 하나로 끝난다.
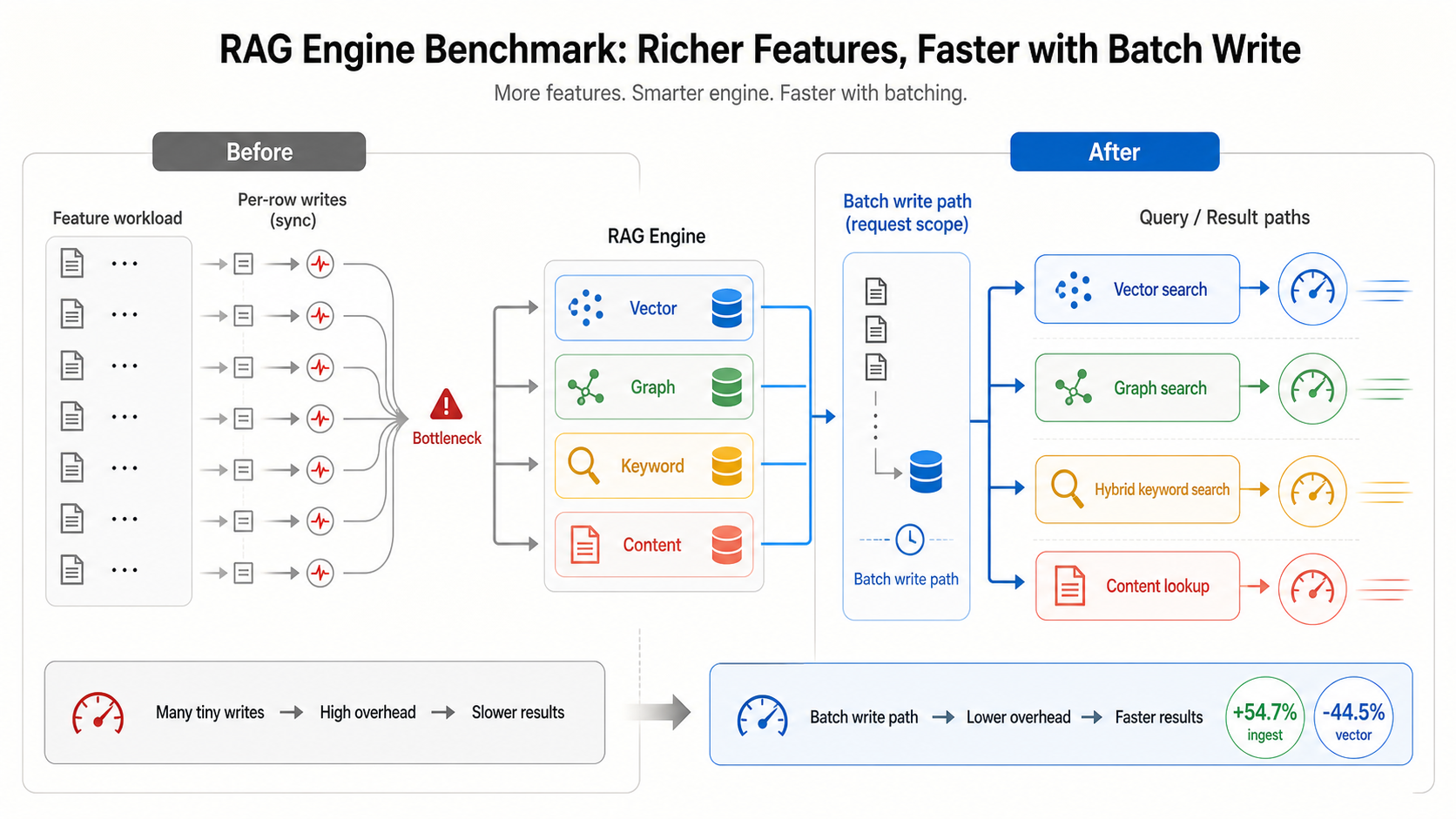
하지만 실제 RAG 시스템에서 엔진이 하는 일은 vector search 하나가 아니다. 문서를 넣고, 원문을 저장하고, keyword index를 만들고, graph edge를 붙이고, 검색 시에는 vector / keyword / graph / content lookup을 같이 탄다.
그래서 이번 benchmark 질문은 이렇게 잡았다.
현재 production engine image와 비교했을 때, 새 engine build는 실제 RAG feature workload에서도 빨라졌는가?
결론부터 말하면, 그렇다.
동일한 amd64 Docker image 조건, 동일한 gRPC benchmark harness에서 새 build는 현재 production image 대비 ingest throughput을 54.7% 높였고, vector search latency를 44.5% 낮췄다. Graph search, hybrid keyword search, content lookup도 모두 20–39% 빨라졌다.
비교 대상
이번 비교의 baseline은 과거 source tree가 아니라 현재 production에서 쓰는 engine image다.
비교 대상은 같은 코드 라인의 새 build다. 둘 다 Docker에서 linux/amd64로 실행했다. Apple Silicon host에서 native arm64 binary와 비교하면 숫자가 섞이기 때문에, 그 결과는 제외하고 amd64 image끼리만 비교했다.
검증에는 내부 engine 측정 프레임워크를 사용했다. 단순히 함수 하나를 직접 호출하는 microbenchmark가 아니라, gRPC 요청이 engine server를 거쳐 저장·검색 경로까지 내려가는 형태로 측정했다.
Workload
단순 vector-only workload가 아니다.
이번 benchmark는 다음 기능을 같이 넣었다.
- vector upsert
text_content포함 upsert- internal FTS indexing
- content store write
- graph edge insert
- vector search
- graph search
- hybrid keyword search
- content batch lookup
측정 조건은 다음과 같다.
validation framework: internal engine measurement frameworkdimension: 1024vectors: 100,000queries: 1,000warmup queries: 100top_k: 10chunk size: 1,000feature workload: enabledruntime: linux/amd64 DockerAPI path: gRPC결과
| Metric | Production image | New build | Change |
|---|---|---|---|
| Build time | 57.61s | 37.24s | -35.4% |
| Insert throughput | 1,735.9 vec/s | 2,685.4 vec/s | +54.7% |
| Vector search avg | 4,757µs | 2,639µs | -44.5% |
| Graph search avg | 5,439µs | 4,326µs | -20.5% |
| Hybrid keyword avg | 3,276µs | 2,267µs | -30.8% |
| Content get_many avg | 574µs | 352µs | -38.7% |
| Query wall time | 14.71s | 9.87s | -32.9% |
가장 큰 변화는 ingest다.
Production image는 feature workload 기준 1,735.9 vec/s였고, 새 build는 2,685.4 vec/s였다. 같은 workload에서 54.7% 더 많이 넣는다.
검색도 vector-only만 좋아진 것이 아니다.
- vector search: 44.5% latency reduction
- graph search: 20.5% latency reduction
- hybrid keyword search: 30.8% latency reduction
- content lookup: 38.7% latency reduction
즉 이번 변화는 “특정 microbenchmark 하나만 좋아진 것”이 아니라, RAG feature path 전반에서 개선이 보인다.
왜 feature workload가 중요한가
RAG engine을 vector search만으로 보면 쉬운 결론이 나온다.
빠른 ANN index를 만들고, vector를 넣고, top-k를 반환하면 된다.
하지만 production RAG에서는 그걸로 부족하다. 검색 결과가 왜 나왔는지 보여줘야 하고, 원문 chunk를 바로 가져와야 하고, keyword match도 필요하고, 문서 구조나 관계 신호도 써야 한다.
그래서 실제 engine path에는 vector write/search 외에도 keyword index, content store, graph relation 같은 계층이 같이 들어간다.
이 기능들이 붙으면 engine은 더 유용해지지만, write path와 query path는 더 무거워진다. 이번 작업의 목표는 기능을 덜어내는 것이 아니라, 기능이 붙은 상태에서 다시 빠르게 만드는 것이었다.
무엇이 바뀌었나
핵심은 write path와 batch path다.
기능이 늘어나면서 vector write, graph relation write, content write, keyword indexing이 같은 ingest 흐름에 들어왔다. 이때 request 단위로 묶을 수 있는 일을 row 단위로 처리하면 금방 느려진다.
이번 build에서는 ingest 요청을 더 큰 단위로 처리하도록 batch 흐름을 정리했다. content write도 개별 row 중심이 아니라 request 단위로 묶어서 처리한다.
중요한 점은 저장 포맷을 바꿔서 compatibility risk를 키운 것이 아니라, 기존 format을 유지한 상태에서 commit 범위와 write path를 정리했다는 것이다.
그 결과 production image 대비 ingest throughput이 54.7% 올라갔다.
Graph와 hybrid도 같이 봐야 한다
이번 결과에서 제일 마음에 드는 부분은 graph와 hybrid search도 같이 좋아졌다는 점이다.
Graph search는 vector hit를 seed로 잡고 edge expansion을 탄다. Pure vector search보다 할 일이 많다. 그래서 vector path만 빨라졌다면 graph search 개선폭은 작거나 없을 수 있다.
하지만 benchmark에서는 graph search latency도 20.5% 줄었다.
Hybrid keyword path도 마찬가지다. Schift Engine의 hybrid search는 vector branch와 keyword branch를 내부에서 합친다. 이번 benchmark에서는 keyword-only에 가까운 경로를 보기 위해 vector를 비우고 query text 중심으로 호출했다. 이 경로도 30.8% 빨라졌다.
Content lookup도 38.7% 빨라졌다. RAG에서는 top-k id만 반환하면 끝이 아니다. 답변을 만들려면 결국 원문 chunk를 가져와야 한다. content lookup latency가 줄어드는 것은 end-to-end answer latency에도 직접 영향을 준다.
메모리 숫자는 이번 claim에서 뺐다
이번 글에서는 memory claim을 넣지 않는다.
이유는 단순하다. 이번 비교는 macOS host 위 Docker Desktop에서 amd64 container를 돌린 결과다. client process의 RSS는 안정적으로 볼 수 있지만, container 안 engine server의 resident memory를 host에서 일관되게 비교하기 어렵다.
그래서 이번 글의 claim은 latency와 throughput에만 한정한다.
메모리 benchmark는 별도로 Linux amd64 host에서 container cgroup 기준으로 다시 재야 한다.
결론
이번 결과는 “우리 vector search가 빠르다”보다 조금 더 구체적인 이야기다.
Schift Engine은 vector search만 하는 엔진이 아니다. RAG에 필요한 graph, keyword, content lookup을 같은 engine path 안에 넣고 있다. 기능을 붙이면 보통 느려진다. 이번 작업은 그 느려진 부분을 다시 production baseline보다 빠르게 만든 작업이다.
현재 production engine image와 같은 amd64 Docker/RPC 조건에서 새 build는:
- ingest throughput +54.7%
- vector search latency -44.5%
- graph search latency -20.5%
- hybrid keyword latency -30.8%
- content lookup latency -38.7%
RAG engine은 vector DB 하나로 끝나지 않는다. 좋은 engine은 vector search를 빠르게 하는 동시에, graph, keyword, content path를 production latency 안에 넣어야 한다.
이번 benchmark는 그 방향으로 한 단계 더 간 결과다.
RAG Lab 구독
schift 만들면서 직접 굴린 RAG 실험 일지. 매주 새 실험이 올라옵니다.