RAG Lab
온톨로지가 당신 회사에 필요 없을 가능성이 큰 이유
AI 시대의 의미 인프라라는 말이 자주 빠뜨리는 것들입니다. 온톨로지를 깎아내리려는 글이 아니라, 헷갈리지 않고 결재 전에 확인해야 할 기준을 정리한 글이에요.
지난 1년 사이 온톨로지 마케팅이 다시 강해졌습니다. LLM 환각의 해결책, 데이터 사일로의 종결자, 에이전틱 AI의 가드레일이라는 문장이 자주 보입니다. 슬라이드에는 철학자 이름과 knowledge graph 그림이 같이 나오고, 결론은 대개 “그래서 의미 인프라를 구축해야 합니다”로 닫힙니다.
이 글은 온톨로지가 나쁘다는 글이 아닙니다. 특정 벤더나 컨설팅 회사를 공격하려는 글도 아니에요. 온톨로지는 제자리가 분명한 기술입니다. 다만 마케팅 문장에서는 그 제자리보다 훨씬 넓은 문제를 풀 수 있는 것처럼 보일 때가 많습니다.
그래서 이 글의 질문은 단순합니다.
지금 우리 회사에 필요한 것이 정말 온톨로지인가요, 아니면 검색과 데이터 운영의 기본기를 먼저 정리해야 하는 상황인가요?
아래 기준을 따라가면 답이 꽤 빨리 나옵니다. 대부분의 일반 기업에서는 온톨로지 프로젝트를 크게 시작할 이유가 없습니다. 먼저 RAG 검색 품질, 메타데이터, 권한, 평가, 운영 모니터링을 정리하는 편이 훨씬 빠르고 싸고 검증 가능해요.
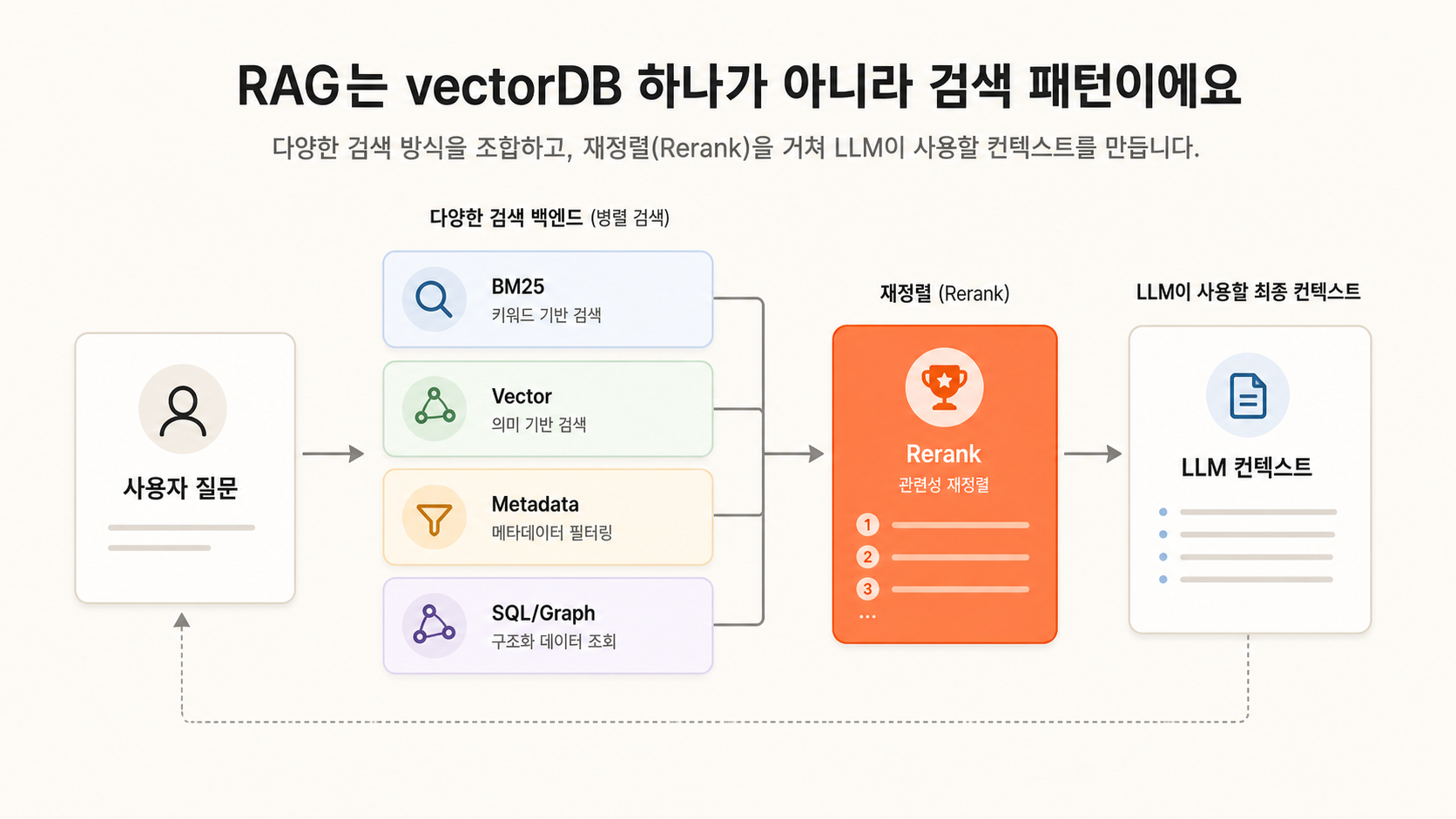
1. “RAG의 한계”는 대개 vectorDB 단독 사용의 한계예요
온톨로지나 GraphRAG 자료에는 이런 비교가 자주 나옵니다.
| 비교 항목 | 기존 RAG | GraphRAG 또는 온톨로지 기반 검색 |
|---|---|---|
| 검색 방식 | 벡터 유사도 | 구조적 관계 검색 |
| 약점 | 환각 가능, 다단계 추론 취약 | 관계와 규칙으로 보완 |
| 결론 | 부족함 | 더 안전함 |
이 표에서 조심해야 할 점은 RAG = vectorDB로 슬쩍 좁혀 놓는다는 것입니다.
RAG는 “외부 근거를 찾아 LLM 컨텍스트에 넣는 패턴”입니다. 검색 backend는 vectorDB일 수도 있고, BM25일 수도 있고, SQL일 수도 있고, graph DB일 수도 있습니다. 실제 운영 시스템에서는 이미 BM25 + vector + metadata filter + reranker를 같이 쓰는 경우가 많습니다.
그러면 “기존 RAG의 한계”라고 부르는 것 중 상당수는 사실 “vectorDB만 단독으로 썼을 때의 한계”입니다. 이 둘은 다릅니다.
예를 들어 “계약 해지 절차”라는 문서를 찾는다고 해보겠습니다. 사용자는 “구독 그만두려면요?”라고 묻습니다. vector 검색만 쓰면 비슷한 말은 잘 잡지만, 정확한 조항명이나 날짜 조건을 놓칠 수 있습니다. 그렇다고 곧바로 온톨로지가 필요한 것은 아닙니다.
보통은 이렇게 먼저 개선합니다.
- BM25로 정확한 용어와 조항명을 잡습니다.
- vector 검색으로 의역과 자연어 질문을 잡습니다.
- metadata filter로 고객사, 권한, 날짜, 문서 타입을 제한합니다.
- reranker로 후보 근거를 다시 정렬합니다.
이것도 RAG입니다. 온톨로지는 이 패턴의 한 선택지일 뿐이에요. “RAG가 부족하니 온톨로지가 필요하다”는 문장은 너무 큰 점프입니다.
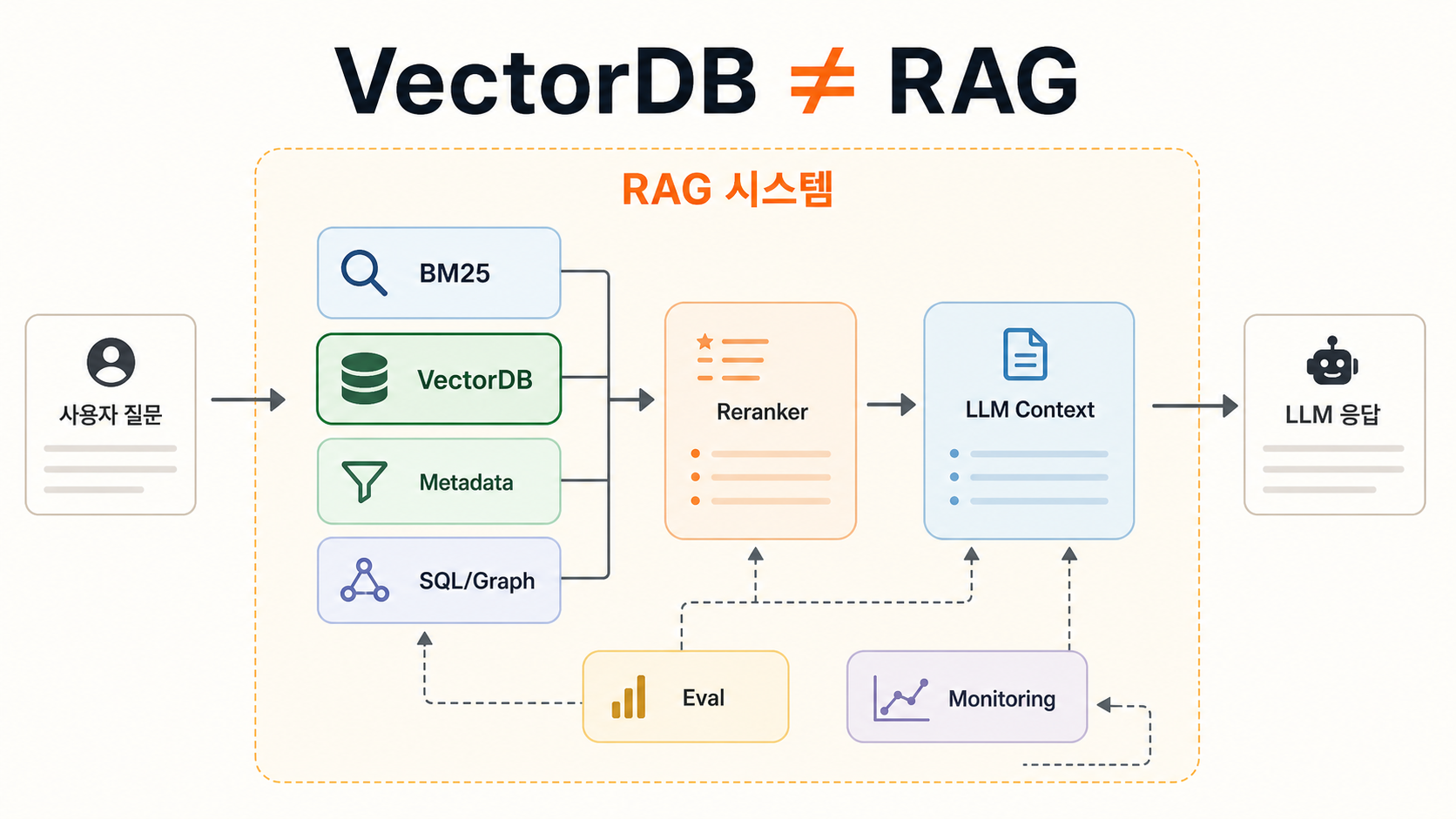
2. vectorDB가 왜 유용했는지를 짧게 넘기면 비교가 틀어집니다
온톨로지 자료는 vectorDB를 “유사도 기반 검색” 정도로 짧게 처리하는 경우가 많습니다. 틀린 말은 아니지만, 왜 vectorDB가 빠르게 채택됐는지를 빼면 비교가 불공정해집니다.
vectorDB 이전에는 비정형 텍스트에서 의미를 찾는 방법이 꽤 고통스러웠습니다.
첫째, 키워드 매칭이 있었습니다. “두통, 어지러움”으로 검색하면 “headache, dizziness”라고 적힌 노트는 못 찾습니다. 동의어 사전을 직접 만들어야 합니다. 그런데 그 사전은 늘 비고, 도메인이 바뀌면 계속 고쳐야 합니다.
둘째, 사람이 코드를 붙이는 방식이 있었습니다. 의료라면 진단 코드, 법무라면 쟁점 코드, 고객지원이라면 이슈 타입을 사람이 붙입니다. 잘 되면 좋지만 입력 누락이 생기고, 사람마다 기준이 다릅니다.
vectorDB는 이 두 길을 우회했습니다. 사전 합의가 없어도 의미가 가까운 문서를 찾을 수 있게 했습니다. 한국어 질문으로 영어 문서를 잡고, 의역을 잡고, “계약 종료”와 “서비스 해지”처럼 부서마다 다르게 쓰는 표현도 어느 정도 묶어줍니다.
이게 중요합니다. 많은 회사가 처음으로 며칠 만에 문서 검색 prototype을 만들 수 있게 된 이유가 바로 여기에 있습니다. 도메인 전문가 워크숍을 열고 분류 체계를 합의하기 전에, 원문을 넣고 검색을 돌릴 수 있게 된 거예요.
정직한 비교는 이렇게 해야 합니다.
vectorDB는 비정형 텍스트의 넓은 부분을 빠르게 열어줍니다. 온톨로지는 합의 가능한 좁은 부분을 더 엄밀하게 다룹니다.
둘은 적이 아닙니다. 문제는 순서예요. 넓은 검색 문제를 아직 풀지 못했는데, 처음부터 전체 온톨로지를 만들겠다고 들어가면 비용이 먼저 커집니다.
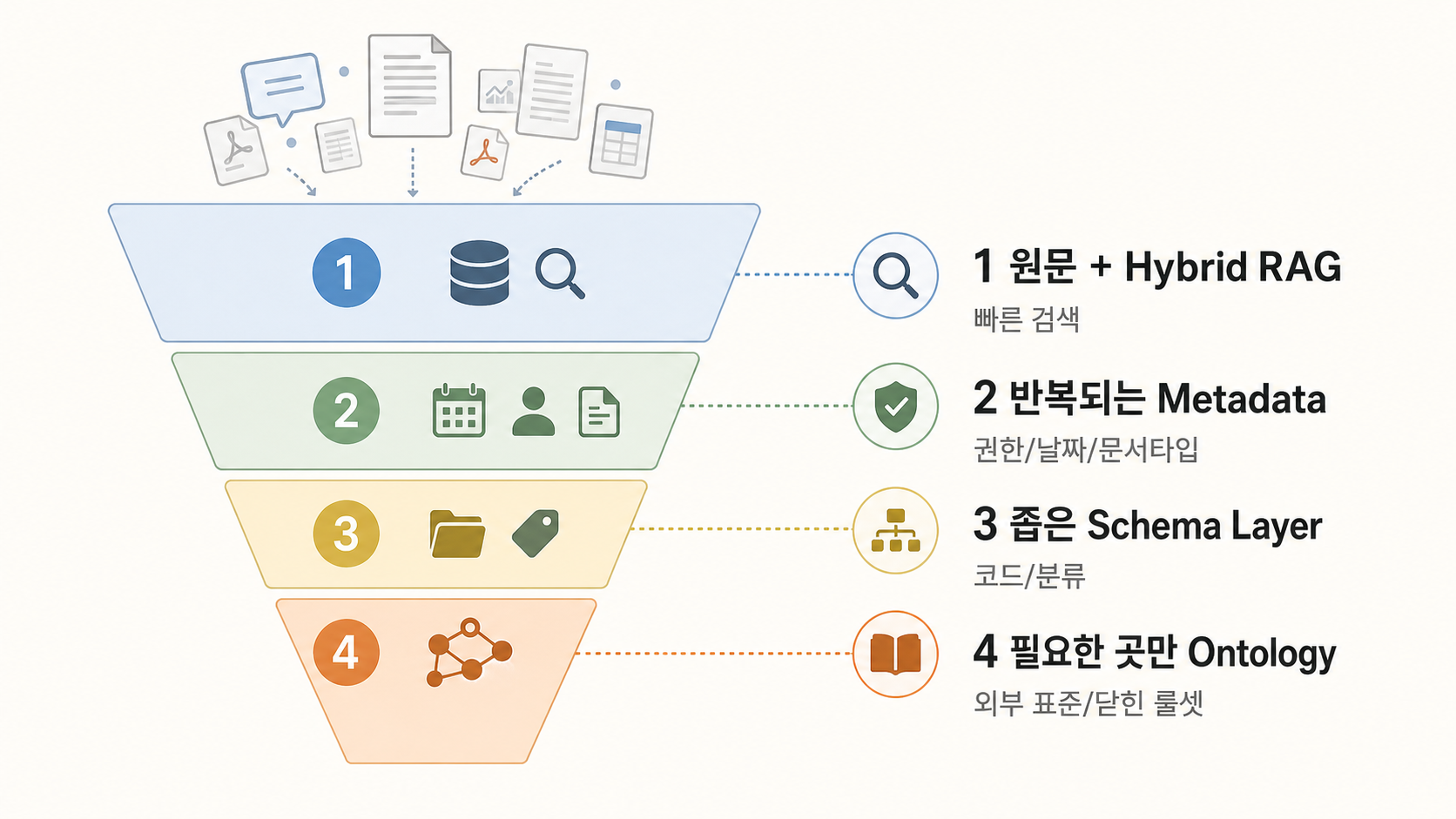
3. 온톨로지는 합의된 도메인에서 힘을 냅니다
온톨로지가 ROI를 내는 영역은 분명합니다. 그 좁음은 결함이 아니라 본분이에요.
- 유전자 기능 분류처럼 학계 합의가 강한 영역
- 약물 상호작용처럼 닫힌 룰셋이 중요한 영역
- ICD, KCD, HS 코드처럼 행정과 규제가 합의를 강제하는 영역
- 도서관 분류나 통제 어휘처럼 합의 자체가 업무인 영역
공통점이 있습니다. 합의를 만드는 비용보다 합의가 주는 이익이 큽니다. 그리고 많은 경우 그 합의는 이미 만들어져 있습니다.
일반 회사의 내부 데이터는 다릅니다.
영업팀이 말하는 customer, 마케팅팀이 말하는 customer, 회계팀이 말하는 customer가 모두 다를 수 있습니다. 이건 데이터 품질이 나쁜 게 아니라 의사결정 맥락이 다른 것입니다. 영업팀에는 아직 계약 전인 리드도 customer처럼 보일 수 있고, 회계팀에는 청구가 시작된 계정만 customer일 수 있습니다.
이 차이를 무조건 하나의 정의로 고정하려고 하면 프로젝트가 곧 조직 합의 프로젝트가 됩니다. 그 자체가 나쁜 것은 아닙니다. 다만 그건 데이터 인프라 구매가 아니라 변경관리와 거버넌스 프로젝트예요.
이런 프로젝트의 흔한 흐름은 꽤 비슷합니다.
- 1개월 차: 클래스 초안이 나옵니다. 각 부서가 “우리는 그렇게 안 부릅니다”라고 말하기 시작합니다.
- 3개월 차: 큰 합의는 미뤄지고 작은 정의만 늘어납니다.
- 6개월 차: 일부 데이터 매핑은 끝났지만 기존 시스템 연결이 남습니다.
- 9개월 차: 새 시스템 도입과 변경관리 이슈가 생깁니다.
- 12개월 차: 관리되지 않는
.ttl파일과 열리지 않는 거버넌스 회의가 남습니다.
이 흐름은 특정 벤더가 나빠서 생기는 문제가 아닙니다. 합의되지 않은 도메인에 합의된 모델을 먼저 씌울 때 자연스럽게 생기는 비용입니다.
4. 의미가 나중에 바뀌는 데이터에는 기록 시점의 합의가 잘 맞지 않습니다
마케팅 데모는 보통 깔끔합니다. “고객 A가 제품 B를 구매했다” 같은 트리플이 나옵니다. 하지만 실제 업무 데이터는 시간이 지나면서 의미가 바뀝니다.
고객지원 예시를 보겠습니다.
- 1일 차: 사용자가 “로그인이 안 됩니다”라고 문의합니다.
- 1일 차 오후: 상담사는 비밀번호 재설정 이슈로 분류합니다.
- 2일 차: 엔지니어는 OAuth callback 설정 문제라고 봅니다.
- 3일 차: 보안팀은 의심스러운 IP 패턴을 보고 계정 보호 이슈로 재분류합니다.
- 5일 차: 고객 성공팀은 이 사건을 엔터프라이즈 온보딩 실패 사례로 기록합니다.
같은 티켓인데 관점이 계속 바뀝니다. 처음에는 인증 문제였고, 다음에는 설정 문제였고, 나중에는 보안 이벤트이자 온보딩 리스크가 됩니다. 어느 하나가 완전히 틀렸다기보다, 시간과 역할에 따라 설명 레이어가 달라진 것입니다.
이런 데이터를 OWL 스타일의 엄밀한 온톨로지로 모델링하려면 곧 복잡해집니다.
- 상태가 필요합니다. suspected, confirmed, superseded 같은 단계가 있어야 합니다.
- 시간이 필요합니다. “그때는 맞았지만 지금은 바뀐 판단”을 표현해야 합니다.
- 의견 충돌을 담아야 합니다. 보안팀과 고객 성공팀의 관점이 동시에 존재할 수 있어야 합니다.
- 재해석을 담아야 합니다. 나중에 들어온 정보가 과거 사건의 의미를 바꿀 수 있어야 합니다.
물론 이론적으로 표현할 수 있습니다. 하지만 그 순간 모델은 커지고, 운영 규칙은 복잡해지고, 사람들은 입력을 피하기 시작합니다. 결국 사용자는 그래프 탐색 화면이 아니라 검색창으로 돌아옵니다.
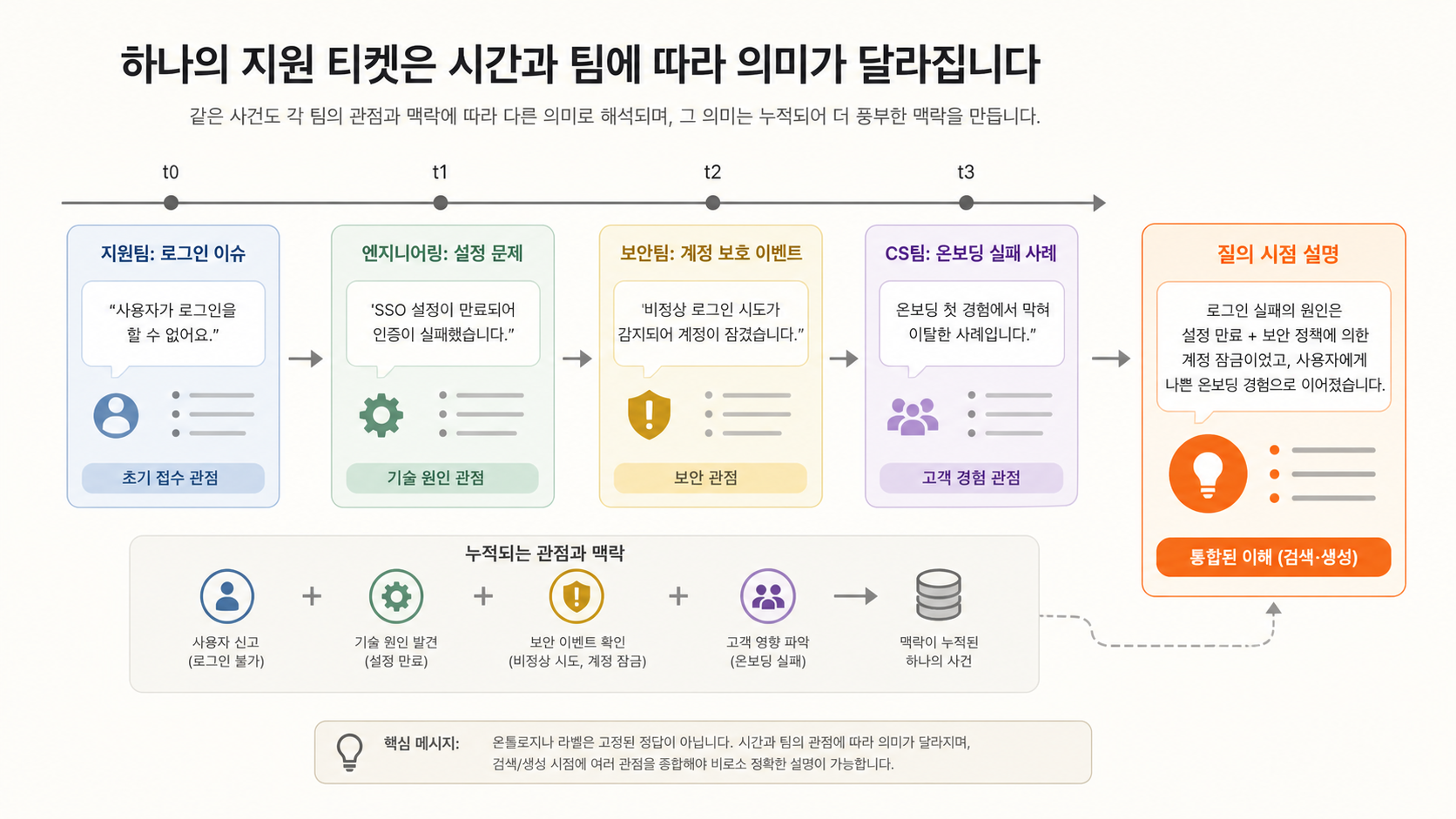
핵심은 이겁니다.
온톨로지는 의미 합의를 기록 시점에 고정하는 데 강합니다. 많은 실무 데이터는 합의가 질의 시점에 다시 만들어집니다.
vectorDB + LLM 방식은 이 합의를 질의 시점으로 미룹니다. “이 고객의 로그인 이슈가 왜 보안 이벤트로 바뀌었나요?”라고 물으면, 티켓, 로그, Slack, CRM 노트를 시간순으로 가져오고 LLM이 근거와 함께 설명합니다. 원문 의견이 살아 있으니 관점 차이도 같이 보여줄 수 있습니다.
회사 데이터의 의미가 시간, 조직, 관점에 따라 흔들린다면 그것은 결함이 아니라 정상입니다. 이 경우에는 전체 온톨로지를 먼저 사기보다, 원문과 메타데이터를 보존하고 검색 품질을 높이는 편이 실용적이에요.
5. 산업 사례가 곧 OWL 온톨로지 채택을 뜻하지는 않습니다
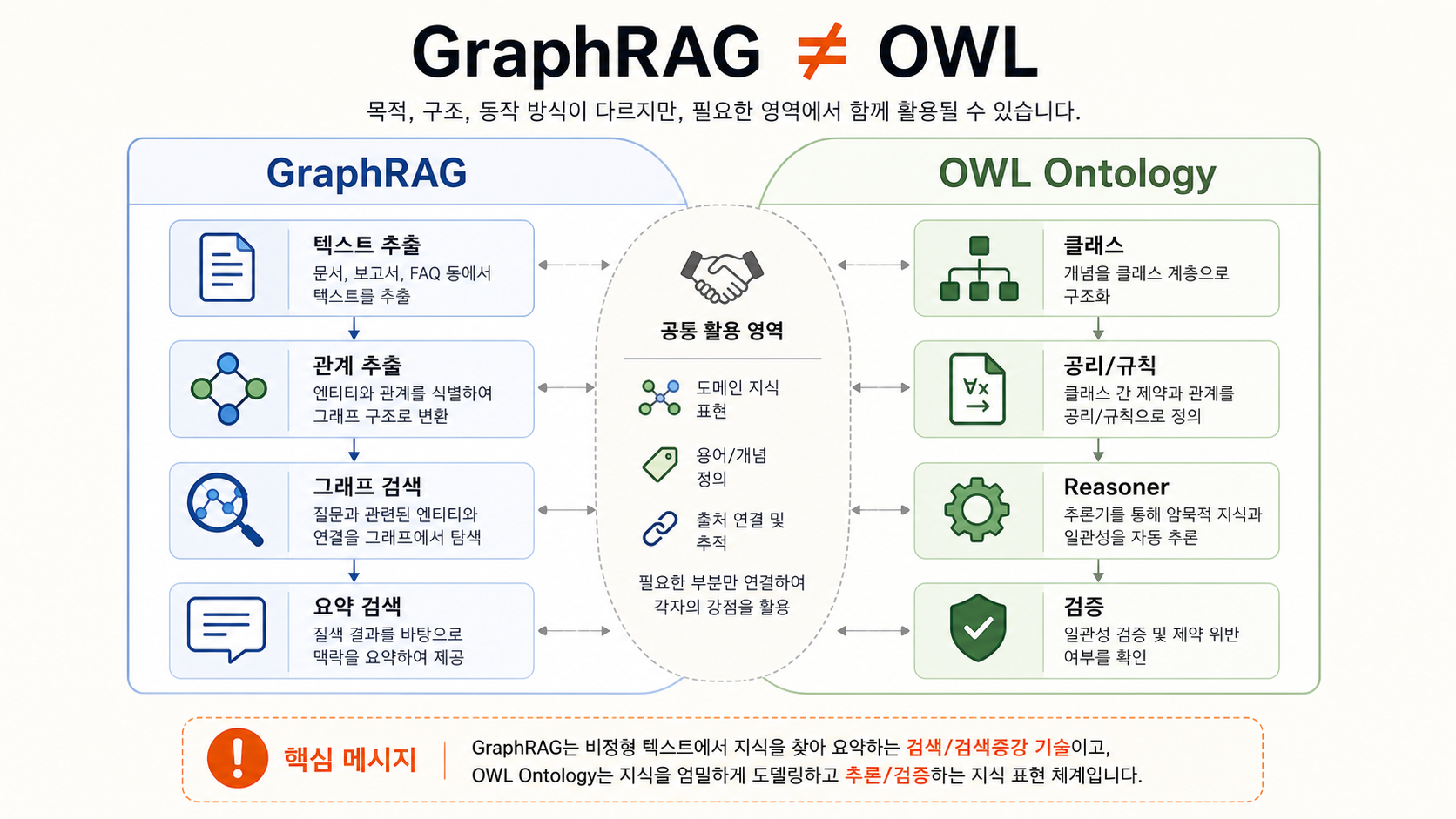
GraphRAG나 knowledge graph 성공 사례를 볼 때는 세 단어를 분리해서 봐야 합니다.
- 온톨로지: 도메인 모델입니다. schema-less부터 SHACL, OWL DL까지 강도가 다양합니다.
- GraphRAG: 그래프를 검색 backend 또는 요약 구조로 쓰는 RAG 패턴입니다.
- GraphDB: 노드와 엣지를 저장하고 탐색하는 저장소입니다.
이 세 축은 서로 다릅니다. OWL 없이 GraphRAG를 만들 수 있습니다. GraphDB에 schema 없이 데이터를 넣을 수도 있습니다. 반대로 vectorDB 위에 강한 메타데이터 schema를 얹을 수도 있습니다.
최근 인용되는 GraphRAG 사례 중 상당수는 LLM으로 엔티티와 관계를 추출하고, property graph로 연결하고, community summary나 traversal 결과를 검색에 쓰는 방식입니다. 이 방식은 유용할 수 있습니다. 다만 그것이 곧 “우리 회사도 OWL + SPARQL + reasoner 기반 온톨로지를 구축해야 한다”는 결론으로 이어지지는 않습니다.
여기서 오개념이 생깁니다. 마케팅 문장에서는 knowledge graph, ontology, graph database, GraphRAG가 한 덩어리처럼 보일 때가 있습니다. 하지만 실제 설계에서는 각각 다른 선택입니다.
벤더가 나쁘다는 뜻이 아닙니다. 많은 벤더는 graph 기반 검색을 잘 구현합니다. 다만 구매자는 “이 사례가 정확히 어떤 기술 스택을 썼는지”와 “우리에게 필요한 것도 같은 층위인지”를 따로 확인해야 합니다.
6. “온톨로지로 만들었다”는 말의 상당수는 사실 사전이나 인스턴스 그래프입니다
가장 깊은 혼동은 여기서 생깁니다.
“우리 회사 데이터를 온톨로지로 정리했습니다.”
“AI 소설 세계관을 온톨로지로 만들었습니다.”
“제품 카탈로그를 온톨로지로 구조화했습니다.”
이 세 문장에서 온톨로지라는 말이 가리키는 것이 모두 다를 수 있습니다. 많은 경우 진짜 온톨로지라기보다 내부 사전, 세계관 사전, 인스턴스 그래프에 가깝습니다.
온톨로지의 본질은 한 단계 위의 분류 체계입니다. “이 도메인에 어떤 종류의 것들이 존재할 수 있고, 어떤 관계가 가능한가”를 정의하는 모델이에요.
예를 들어 창작자가 작품 세계를 정리한다고 해보겠습니다.
- “칼레브는 마법사이고 라엘의 스승입니다.”
- “7장에서 칼레브가 라엘을 배신합니다.”
- “이 세계의 마법은 기억을 대가로 발동됩니다.”
이것은 훌륭한 세계관 사전입니다. 그래프로 그릴 수도 있습니다. 하지만 보통은 온톨로지가 아닙니다. 그 작품 안에서 통하는 사실과 규칙을 정리한 것이기 때문입니다.
진짜 온톨로지에 가까운 것은 한 단계 위의 분류입니다.
- 판타지 장르 캐릭터 유형: 마법사, 전사, 치유자, 암살자
- 마법 시스템 유형: 원소 기반, 룬 기반, 계약 기반, 기억 기반
- 서사 구조 유형: 3막 구조, 영웅의 여정, 옴니버스 구조
다른 작가와 다른 작품에도 재사용될 수 있다면 온톨로지에 가까워집니다. 한 작품 안에서만 통하면 사전입니다.
기업 데이터도 같습니다.
- “우리 고객은 245만 명입니다.” 이것은 인스턴스 사실입니다.
- “우리 회사에서는 가입 후 첫 결제까지 한 사람을 customer로 부릅니다.” 이것은 내부 정의입니다.
- 부서별 정의를 모아놓은 문서는 internal glossary 또는 data dictionary입니다.
다른 회사와 시스템이 그대로 받아 쓸 수 있는 분류 체계라면 온톨로지에 가깝습니다. 한 조직 안에서만 통하면 사전에 가깝습니다.
시금석은 재사용 가능성입니다.
다른 조직이 받아 써도 되는 분류 체계라면 온톨로지에 가깝습니다. 우리 조직 안에서만 통하는 정의 모음이라면 사전이에요.

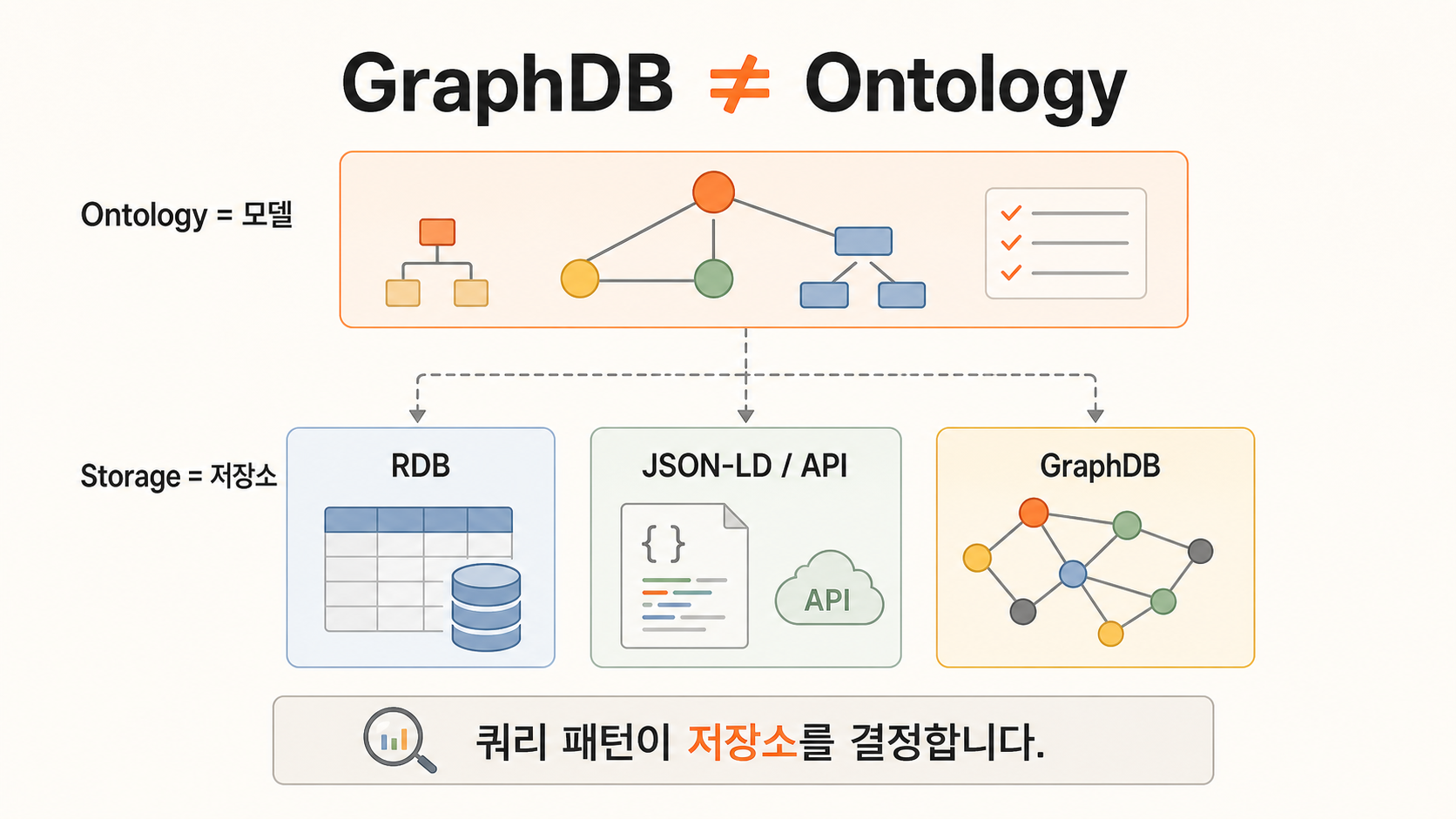
그리고 하나 더 있습니다. 온톨로지는 graph DB와도 다릅니다.
SNOMED CT 같은 의료 표준은 RF2 포맷으로 배포되고, 병원 시스템에서는 RDB에 적재되는 경우가 많습니다. schema.org는 JSON-LD나 microdata로 웹 페이지에 들어갑니다. HL7 FHIR는 JSON과 REST API로 운영됩니다. 회계 계정과목은 ERP의 RDB에 삽니다.
그래프 DB에 저장하지 않아도 도메인 모델은 존재합니다. 반대로 Neo4j에 고객, 주문, 제품 노드를 넣었다고 자동으로 온톨로지가 생기는 것도 아닙니다. 그래프 DB는 저장소이고, 온톨로지는 모델입니다.
저장소는 쿼리 패턴과 운영 요건으로 고르면 됩니다. 깊은 path traversal이 비즈니스 로직이면 graph DB가 맞을 수 있습니다. 청구나 회계처럼 정형 JOIN이 많으면 RDB가 더 맞을 수 있습니다. 웹 SEO라면 JSON-LD가 맞습니다.
7. 그래프 그림은 멋있지만, 결재 근거가 되어서는 안 됩니다
그래프 데모는 강합니다. 가운데 고객 노드가 있고, 제품, 계약, 티켓, 문서, 담당자가 빛처럼 연결됩니다. 클러스터는 색깔별로 나뉘고, 마우스를 올리면 노드가 움직입니다. 임원 회의에서 이런 화면은 설득력이 있습니다.
반대로 embedding 공간을 UMAP으로 보여주면 감탄이 덜합니다. 점들의 군집은 분석가에게는 의미 있지만, 결재자에게는 그냥 점처럼 보일 수 있습니다.
이 미적 차이는 실제 의사결정에 영향을 줍니다. 그래서 더 조심해야 합니다.
운영 환경에서는 그래프 시각화가 생각보다 빨리 한계에 부딪힙니다.
- 100개 노드를 넘으면 화면이 복잡해집니다. 실제 시스템은 수만, 수백만 노드입니다.
- 사용자는 대개 그래프를 직접 보지 않습니다. 검색 결과, 답변, 알림, 업무 화면을 봅니다.
- 실제 query는 1~2 hop인 경우가 많습니다. 이 정도는 SQL JOIN과 metadata filter로도 충분합니다.
- 모든 것이 “회사”, “고객”, “문서” 같은 hub node에 연결되면 traversal 결과가 금방 넓어집니다.
그래프가 필요 없는 것은 아닙니다. 사기 탐지, 자금세탁, 권한 전파, 공급망 리스크처럼 깊은 관계 탐색이 비즈니스 로직인 영역에서는 강합니다. 다만 “그래프가 멋있다”와 “우리 운영 문제의 최선 해결책이다”는 다른 문장입니다.
비용은 어떻게 다를까요
아래 표는 결재 전에 보는 현실적인 비교입니다. 숫자는 조직과 데이터 크기에 따라 달라지지만, 상대적인 비용 구조는 대체로 비슷합니다.
| 항목 | 온톨로지 OWL / SPARQL 중심 |
Property graph Neo4j 등 |
VectorDB + LLM Hybrid RAG |
|---|---|---|---|
| 초기 구축 | 도메인 전문가와 온톨로지 엔지니어가 필요합니다. 보통 수개월 단위입니다. | 데이터 모델링과 ETL이 필요합니다. 관계 탐색이 명확할 때 적합합니다. | 원문 적재, 임베딩, 검색, rerank부터 시작할 수 있습니다. 첫 결과가 빠릅니다. |
| 입력 매핑 | 표준 코드와 내부 데이터를 매핑해야 합니다. 사람 입력 누락이 생기기 쉽습니다. | 노드 타입과 엣지 타입 정의가 필요합니다. 운영 중 schema drift가 생깁니다. | 원문을 유지한 채 metadata만 붙여 시작할 수 있습니다. |
| 변경 비용 | 클래스와 규칙 변경이 reasoner, 매핑, 거버넌스를 건드립니다. | 노드/엣지 타입 변경과 재처리 비용이 있습니다. | 문서 변경분 재임베딩과 index 갱신이 중심입니다. |
| 운영 인력 | 거버넌스와 모델 관리자가 계속 필요합니다. | 데이터 엔지니어와 graph 모델 관리가 필요합니다. | 검색 품질 평가, 권한, 모니터링 운영이 핵심입니다. |
| 잘 맞는 영역 | 표준 분류, 닫힌 룰셋, 규제 보고, 코드 매핑입니다. | 사기 탐지, 계정 관계, 공급망, 깊은 path traversal입니다. | 비정형 문서 검색, QA, 지식 검색, 업무 assistant입니다. |
| 결재 회의 인상 | 엄밀하지만 무겁게 보입니다. | 시각적으로 강합니다. | 덜 화려하지만 사용자 앞 결과가 빠릅니다. |
마지막 행은 원래 비용 표에 들어가면 안 될 것처럼 보입니다. 하지만 실제 결재에서는 중요합니다. 그래프 화면이 멋있어서 통과되는 안건이 있고, 검색 품질 개선은 덜 멋있어서 밀리는 경우가 있습니다. 그래서 이 변수도 의식적으로 분리해서 봐야 합니다.
그럼 어떤 회사에는 온톨로지가 필요할까요
온톨로지가 필요한 회사는 분명히 있습니다. 다만 범위가 좁습니다.
- 분류 자체가 제품인 회사입니다. 의약품 데이터베이스, 화학물질 카탈로그, 생물학 표준 어휘 같은 영역입니다.
- 규제 보고나 청구 코드가 핵심인 회사입니다. ICD, KCD, FHIR, HS 코드처럼 외부 표준이 이미 존재합니다.
- 닫힌 룰셋 추론이 핵심인 시스템입니다. 이때도 OWL이 아니라 SHACL, 룰 엔진, RDB constraint가 더 실용적일 수 있습니다.
- 제품 카탈로그 SEO가 중요한 커머스입니다. 이 경우에도 schema.org를 재사용하면 됩니다.
- 관계 탐색 자체가 제품 가치인 영역입니다. 사기 탐지, 자금 세탁 탐지, 소셜 네트워크 분석, 권한 전파 같은 문제입니다.
이 범위에 들어간다면 온톨로지나 graph 설계가 좋은 선택일 수 있습니다. 하지만 그래도 순서는 같습니다. 먼저 산업 표준이 있는지 확인하고, 있으면 재사용하고, 부족한 부분만 작게 확장해야 합니다.
반대로 일반 기업 지식검색, 사내 문서 QA, 고객지원 assistant, 영업 enablement, 정책 검색 같은 문제라면 대부분은 hybrid RAG부터 시작하는 편이 맞습니다. 실제 사용자가 묻는 질문을 모으고, 검색 품질을 측정하고, metadata와 권한을 정리하고, 필요한 좁은 지점에만 schema layer를 얹으면 됩니다.
컨설팅 제안을 들을 때 물어볼 질문
다음 미팅에서 슬라이드가 넘어갈 때 아래 질문을 해보세요. 공격적인 질문이 아니라 범위를 맞추는 질문입니다.
- “기존 RAG의 한계”라고 하신 것은 vectorDB 단독 사용의 한계인가요, BM25 + vector hybrid까지 포함한 한계인가요?
- 인용하신 GraphRAG 사례가 OWL 추론을 사용했나요, 아니면 property graph + LLM extraction인가요?
- 우리 도메인에는 이미 재사용 가능한 표준이 있나요, 아니면 조직 합의를 새로 만들어야 하나요?
- 우리가 만들 결과물은 다른 회사나 외부 시스템도 재사용할 수 있나요, 아니면 내부 glossary인가요?
- graph DB가 정말 최선의 저장소인가요? RDB, JSON-LD, FHIR API, search index가 더 적합하지 않은 이유는 무엇인가요?
- 첫 사용자가 결과를 보기까지 며칠이 걸리나요?
- 구축 후 누가 definition, mapping, rule 변경을 승인하고 운영하나요?
이 질문 중 몇 개에서 답이 흔들리면, 프로젝트를 사지 말라는 뜻은 아닙니다. 다만 범위를 줄여야 한다는 뜻입니다. “전사 온톨로지”가 아니라 “청구 코드 매핑 schema”, “제품 카탈로그 schema.org 확장”, “고객지원 티켓 graph 탐색”처럼 이름을 작게 바꿔야 합니다.
먼저 할 일은 더 작고 지루합니다
대부분의 회사가 지금 해야 할 일은 더 작고 덜 화려합니다.
- 원문 문서를 잃지 않게 저장합니다.
- 권한과 tenant boundary를 검색 단계에서 강제합니다.
- BM25, vector, metadata filter를 같이 씁니다.
- reranker로 근거 후보를 줄입니다.
- 정답 세트를 만들고 검색 품질을 측정합니다.
- 실제 사용 로그에서 실패 질문을 모읍니다.
- 합의가 반복해서 필요한 좁은 영역만 schema로 승격합니다.
이 순서가 맞습니다. 처음부터 모든 의미를 고정하려고 하지 마세요. 의미가 안정적으로 반복되는 곳이 보일 때만 그 부분을 모델로 올리면 됩니다.
온톨로지는 좋은 도구입니다. 다만 모든 데이터 문제의 출발점은 아닙니다. 특히 AI 시대에는 “의미를 미리 완전히 합의한다”보다 “원문을 보존하고, 검색으로 근거를 모으고, 질의 시점에 설명한다”가 더 빨리 작동하는 경우가 많습니다.
이런 RAG 운영 글을 계속 받아보고 싶으시면 아래에서 RAG Lab을 구독해주세요. 새 글은 블로그와 뉴스레터로 같이 보낼 예정이에요.
RAG Lab 구독
schift 만들면서 직접 굴린 RAG 실험 일지. 매주 새 실험이 올라옵니다.